Support resources developed specifically for use during and after the COVID outbreak.
Spreadsheets to assist with risk assessments and reviews of your security standing.
Videos developed for educational and awareness training.
Awareness training strategies and presentations and more to help implement information security in your organization.
Vendor Risk
Know your vulnerabilities before others do
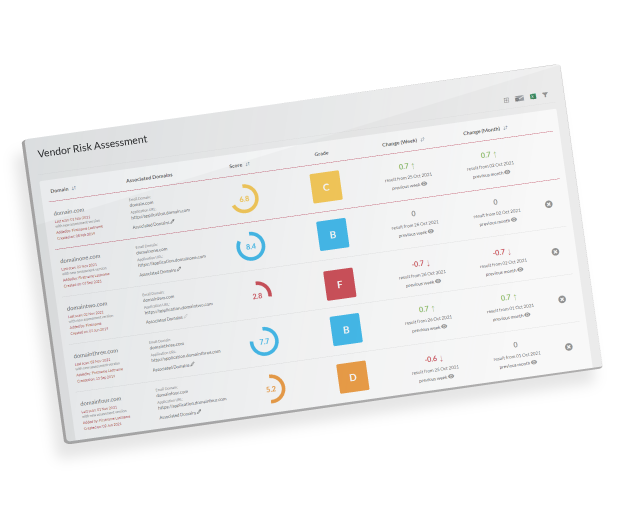
The Vendor Risk Assessment monitors your internet facing domains and those of selected vendors, for misconfiguration and vulnerabilities, and for malicious activity in those domains.
Gain immediate insight into potential vulnerabilities of your public facing infrastructure.
Gain better visibility of the external security standing of your suppliers.
Track the potential risk to your associated suppliers over time.
Maturity Assessment
Get Realistic and Actionable Guidance
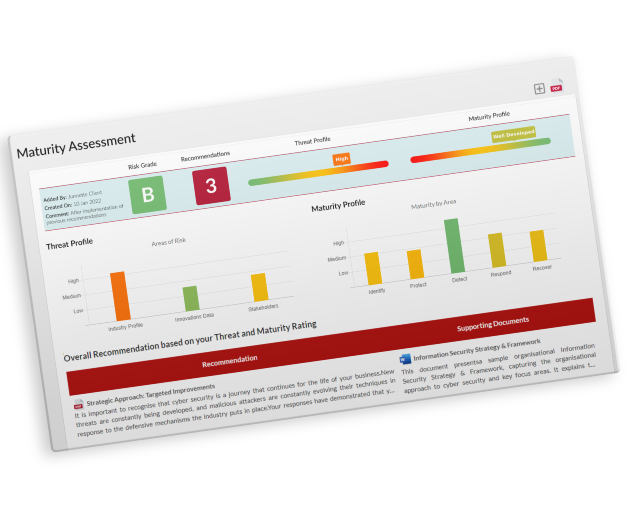
Completing our NIST CSF-based Security Maturity Assessment will direct you to the security projects and documents that will help with your continuous improvement strategy.
Threat and Maturity Assessment and recommendations for prioritized focus on areas of weakness.
Use the documents and score to justify the budgets for your next important security projects.
Show your internal and external stakeholders how your security program is progressing.
Track your maturity improvement over time
Ransomware Readiness Assessment
Get Realistic and Actionable Guidance
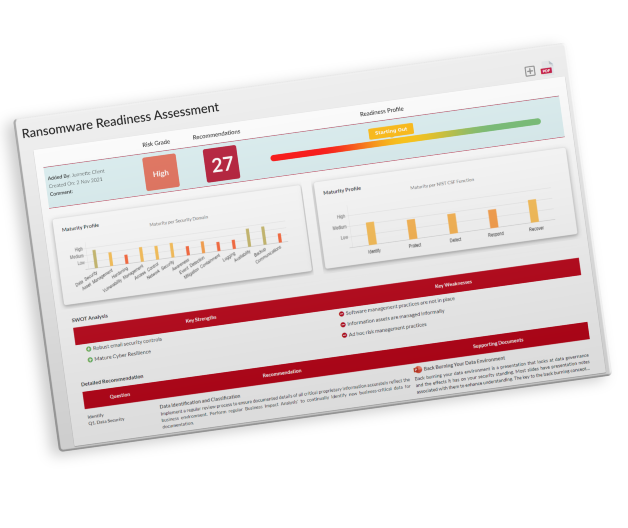
Completing our NIST CSF-based Readiness Assessment will direct you to the appropriate resources that will help with your continuous improvement strategy.
Key strength and weakness assessment results allow prioritized focus on areas of weakness.
Use the key weaknesses and recommended actions to align security budgeting.
Show your internal and external stakeholders how your security program is progressing.
Track your readiness improvement over time
Breach Monitor
Know when your domain appears on the dark web
Ensure you know when and if your domains and related entities are referred to on the dark web with continual monitoring across various breach and ransomware sources.
Include your domain and your vendor’s domains in daily breach monitoring.
Have your breach notifications arrive by email when they occur.
See all public and dark web data sources for occurrences of company email addresses and the associated sites of use.
Security Forum
Your Personal Security Consultant
A few minutes now could save you hours later. Ask our experts for quick advice without having to worry about creating a project or being invoiced for a little help.
Your security questions answered quickly, concisely and accurately.
The Security Forum is included in your subscription.
A private Security Forum is included in Core & Enterprise subscriptions.
Subscription Pricing
Security Colony is the CISO’s best friend, an arsenal of potent, actionable, best practice knowledge
at your finger tips starting at less than $10 a day, and a simple no-fuss pricing model.
Users
Resource Library
Video Library
Vendor Risk
Maturity Assessment
Ransomware Readiness Assessment
Breach Monitor
Security Forums
Included Consulting
free
$0/mo
single user
70+ free resources
18 free educational videos
A single assessment for your email domain
A single assessment (high level reporting)
-
-
Public
-
startup
$150/mo
(charged annually, plus tax)
single user
200+ resources
+ premium educational videos
Assessment of your email domain, continually re-evaluated
(more available with in app purchase)
Get 4 assessments per year
Get 4 assessments per year
Full Monitoring
Public
-
core
$450/mo
(charged annually, plus tax)
five users
400+ resources
+ premium educational videos
+ 10 vendor slots
(more available with in app purchase)
Get 12 assessments per year
Get 12 assessments per year
Full Monitoring
Public & Private Forums
2 document reviews annually
enterprise
$1750/mo
(charged annually, plus tax)
ten users
430+ resources
+ premium educational videos
+ 100 vendor slots
(more available with in app purchase)